Monitoring
How to monitoring nodes in Pigsty and setup alerting rules
Module:
Categories:
Dashboard
There are 6 dashboards for NODE module.
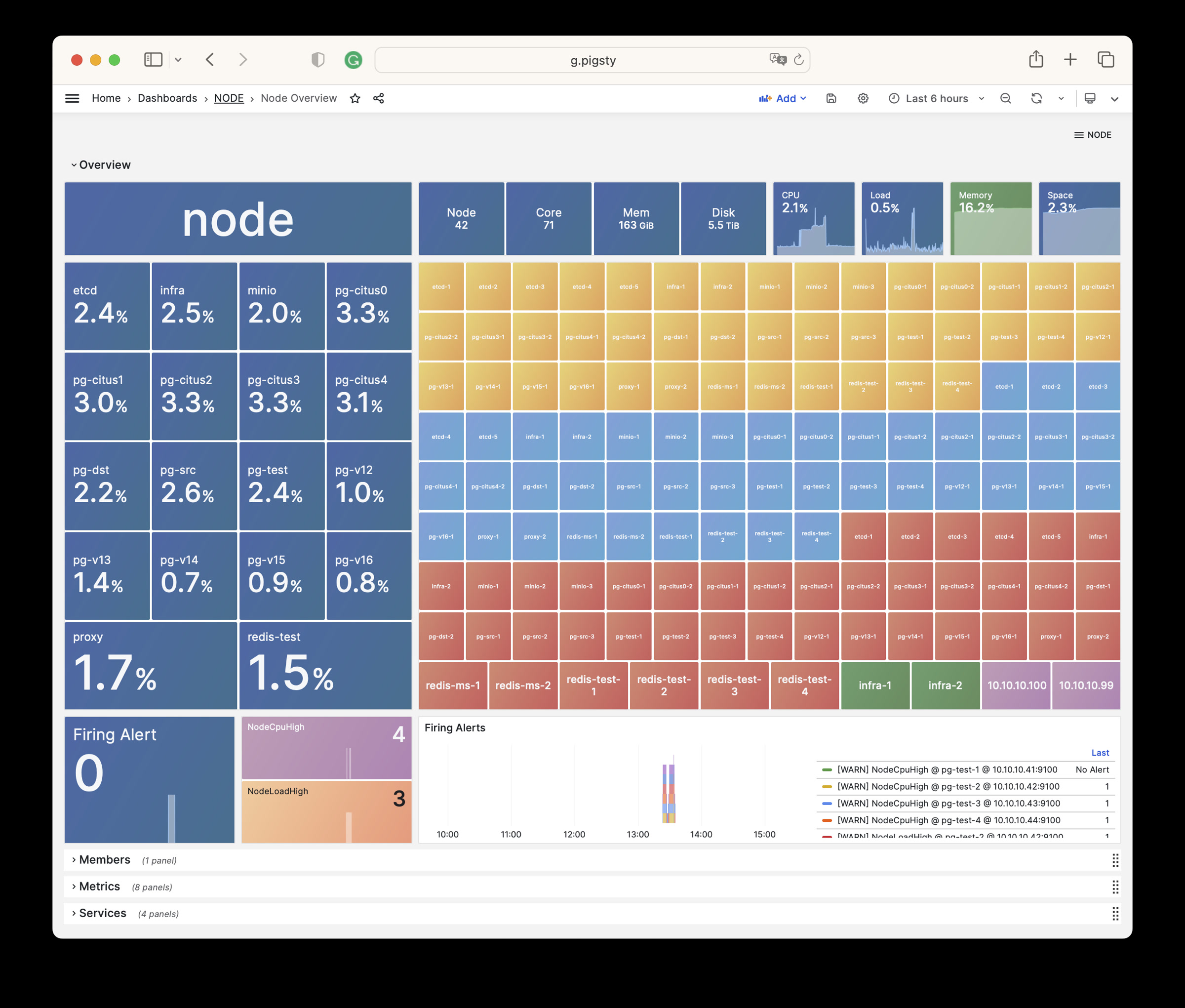
NODE Overview: Overview of all nodes
Node Overview Dashboard
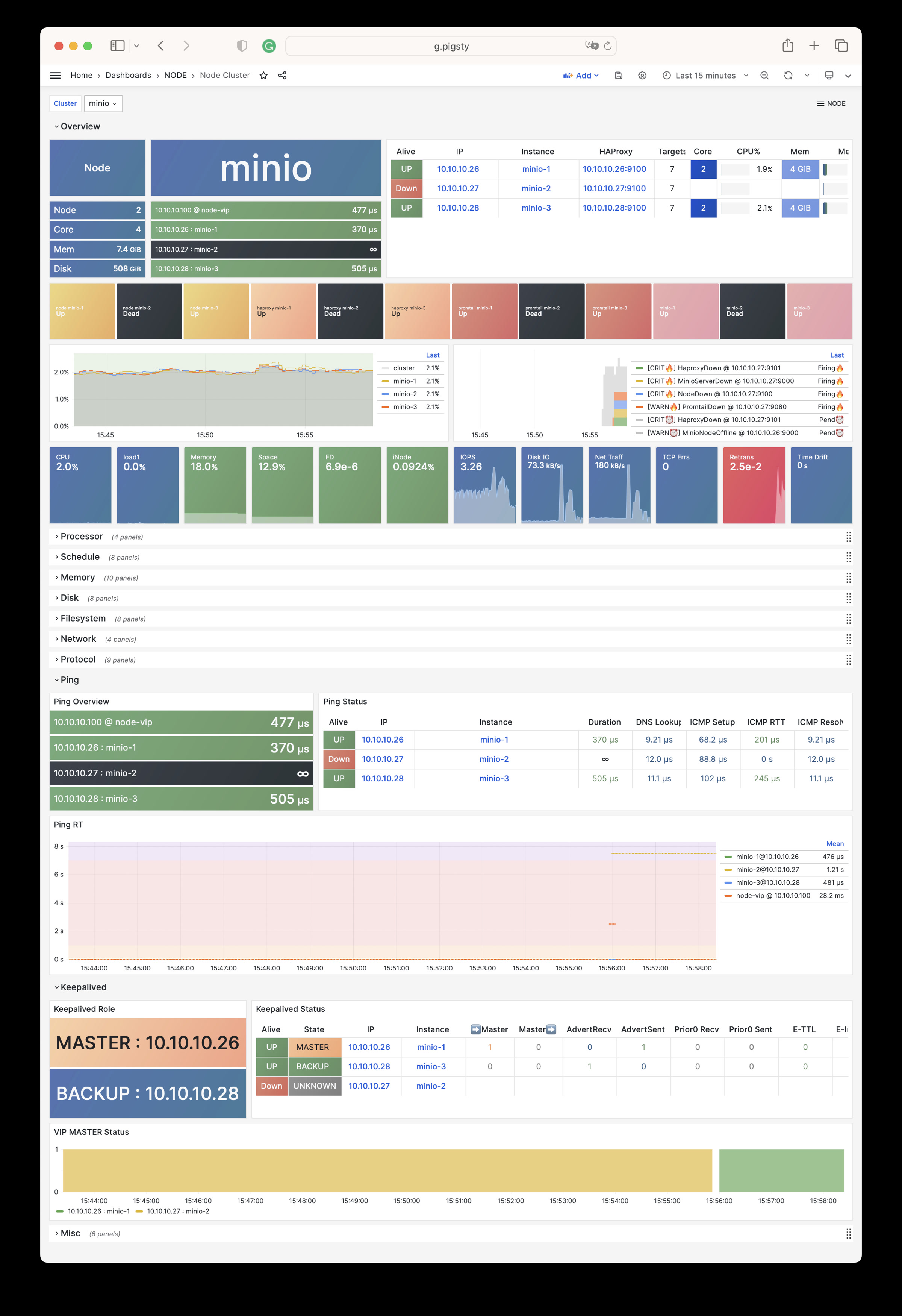
NODE Cluster: Detail information about one dedicate node cluster
Node Cluster Dashboard
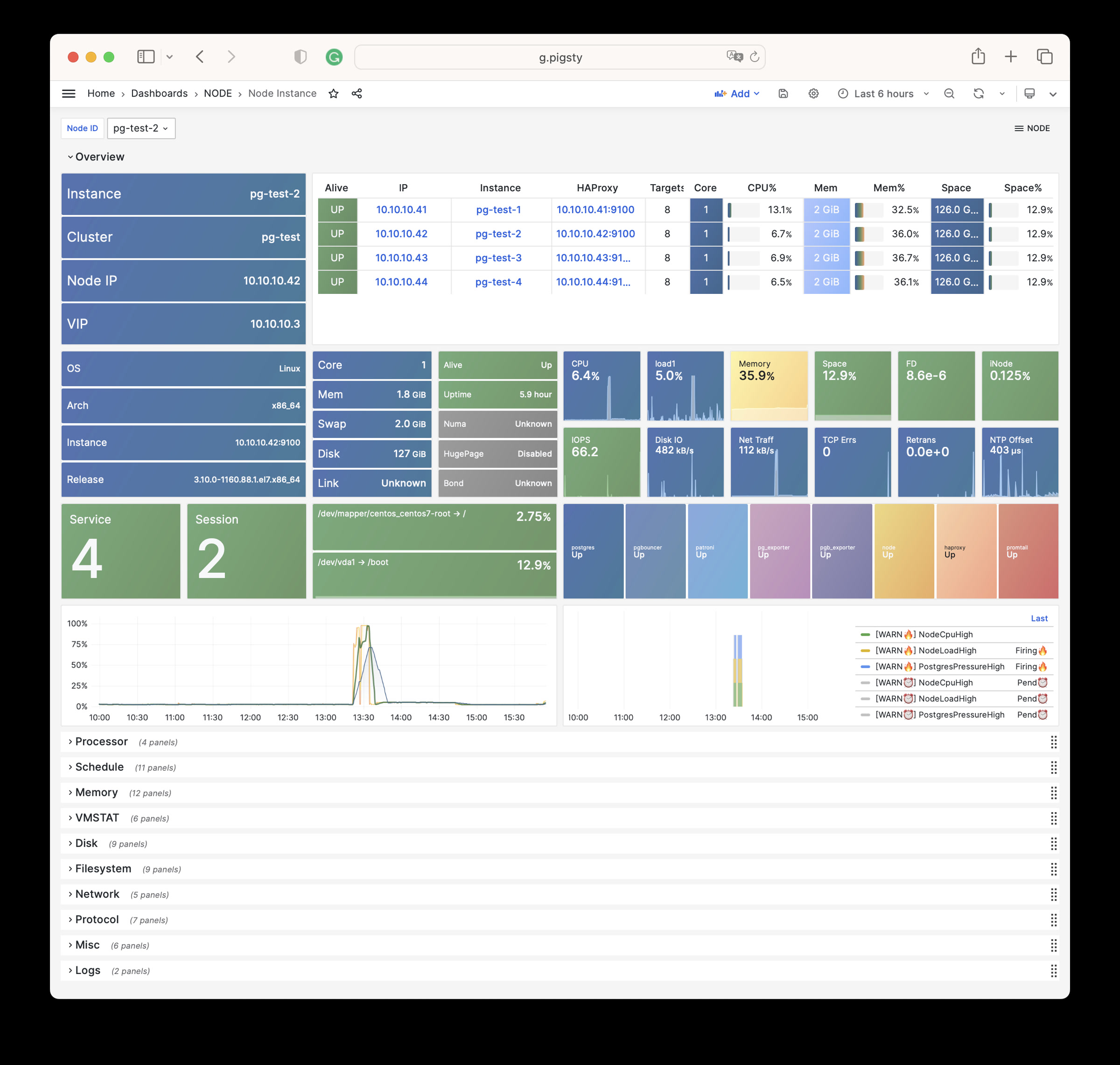
Node Instance : Detail information about one single node instance
Node Instance Dashboard
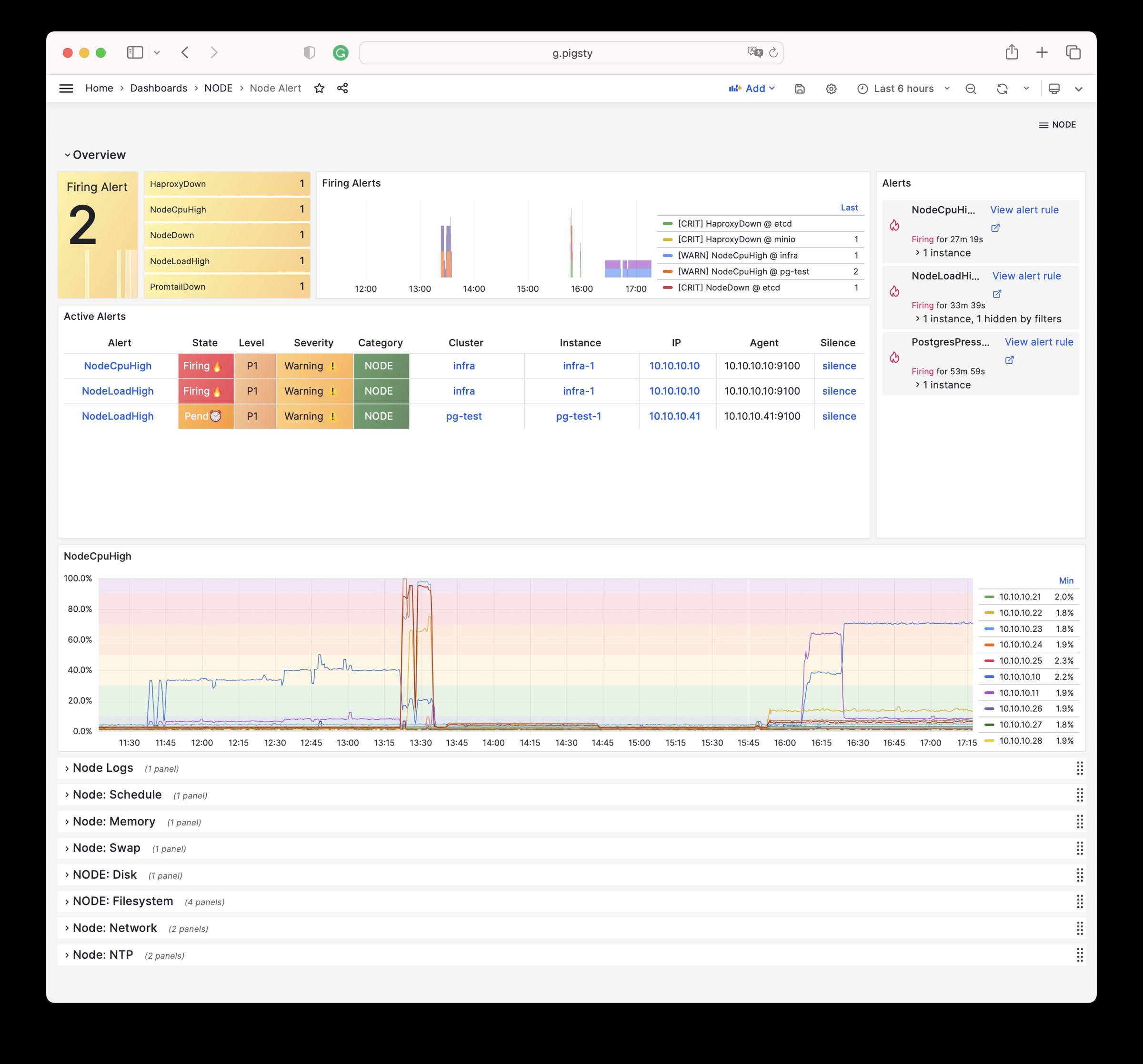
NODE Alert: Overview of key metrics of all node clusters/instances
Node Alert Dashboard
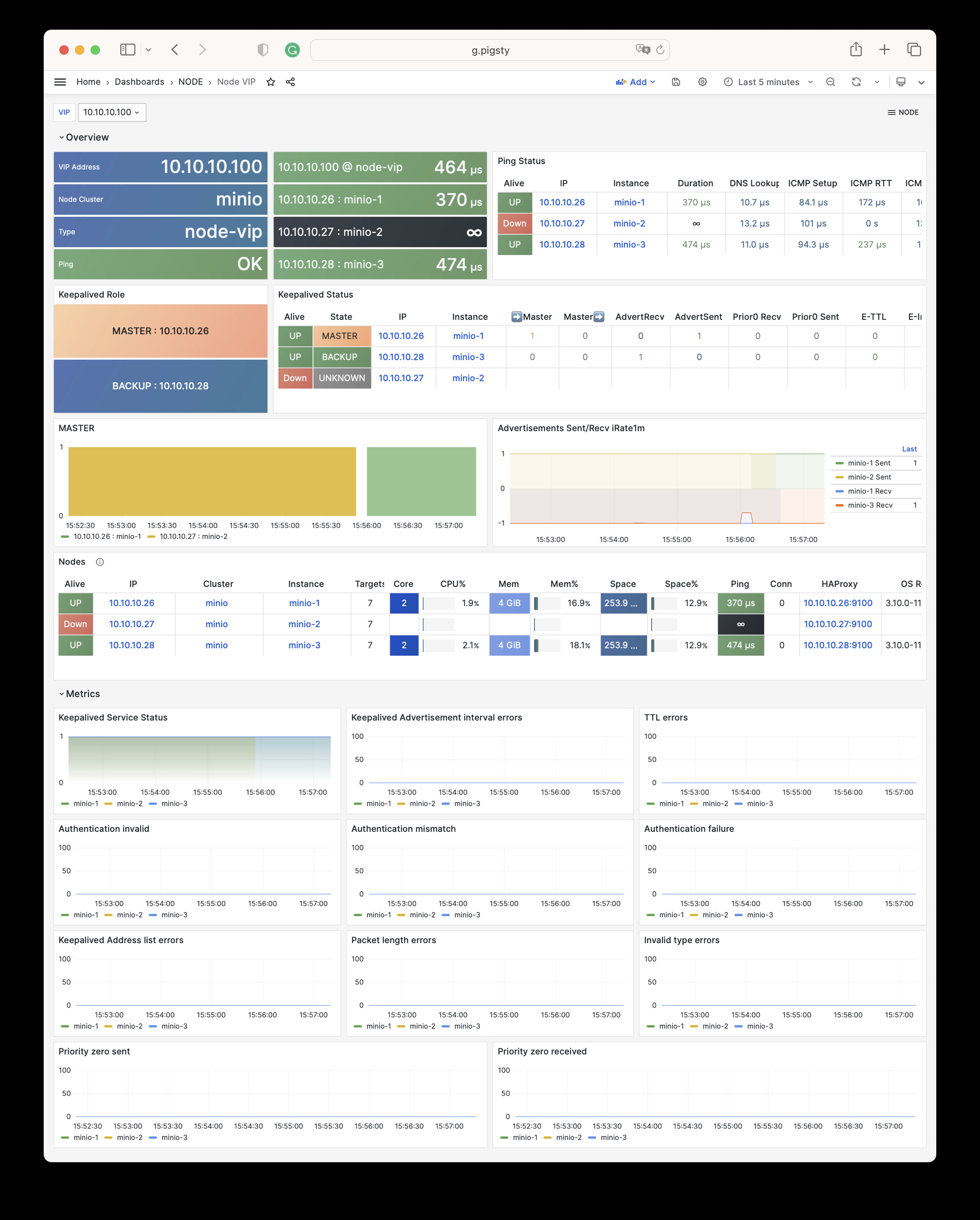
NODE VIP: Detail information about a L2 VIP on a node cluster
Node VIP Dashboard
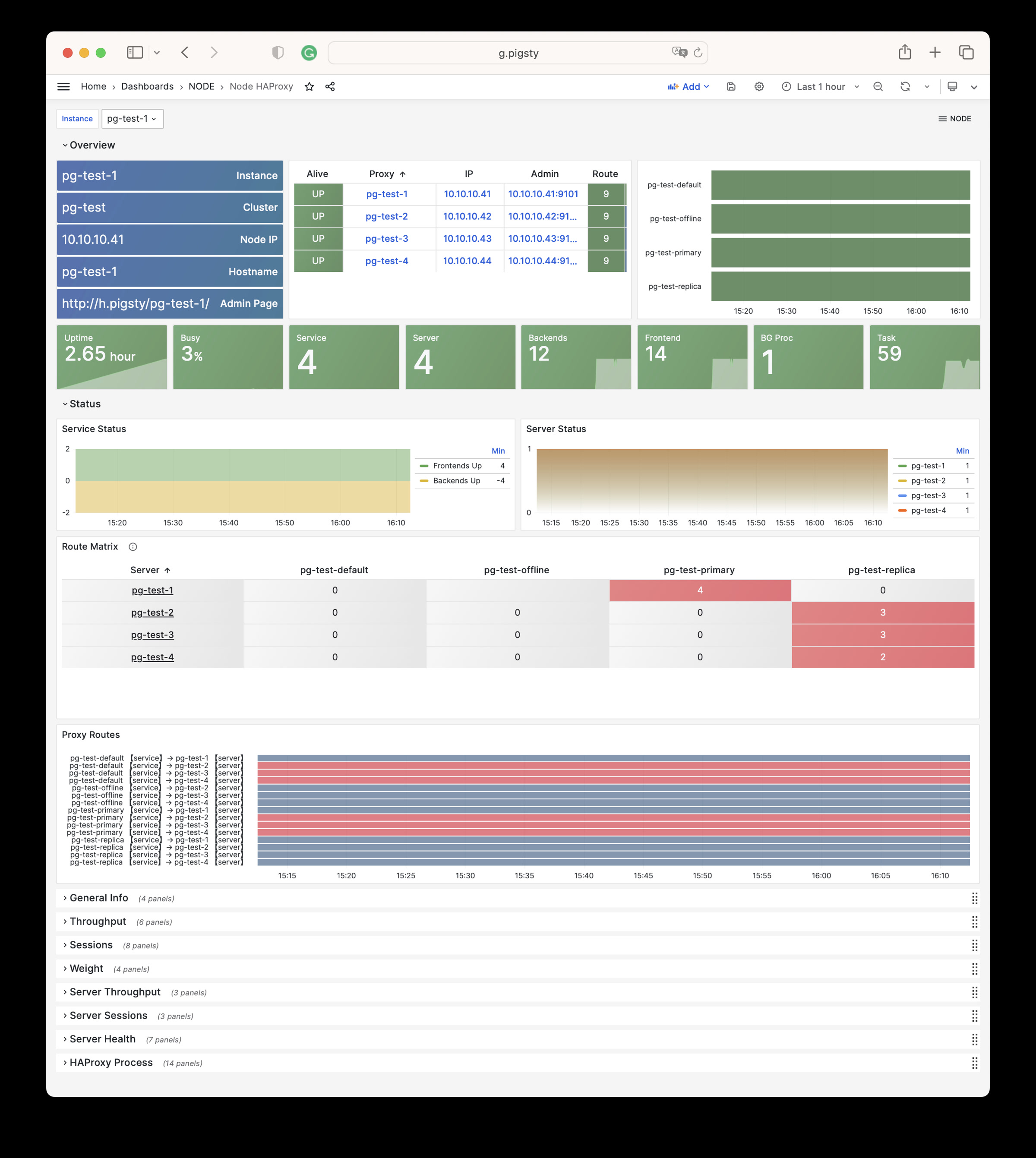
Node Haproxy : Detail information about haproxy on node instance
Node Haproxy Dashboard
Alert Rules
Here are default alerting rules for node module:
################################################################
# Node Alert #
################################################################
- name: node-alert
rules:
#==============================================================#
# Aliveness #
#==============================================================#
# node exporter is dead indicate node is down
- alert: NodeDown
expr: node_up < 1
for: 1m
labels: { level: 0, severity: CRIT, category: node }
annotations:
summary: "CRIT NodeDown {{ $labels.ins }}@{{ $labels.instance }}"
description: |
node_up[ins={{ $labels.ins }}, instance={{ $labels.instance }}] = {{ $value }} < 1
http://g.pigsty/d/node-instance?var-ins={{ $labels.ins }}
# haproxy the load balancer
- alert: HaproxyDown
expr: haproxy_up < 1
for: 1m
labels: { level: 0, severity: CRIT, category: node }
annotations:
summary: "CRIT HaproxyDown {{ $labels.ins }}@{{ $labels.instance }}"
description: |
haproxy_up[ins={{ $labels.ins }}, instance={{ $labels.instance }}] = {{ $value }} < 1
http://g.pigsty/d/node-haproxy?var-ins={{ $labels.ins }}
# promtail the logging agent
- alert: PromtailDown
expr: promtail_up < 1
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: "WARN PromtailDown {{ $labels.ins }}@{{ $labels.instance }}"
description: |
promtail_up[ins={{ $labels.ins }}, instance={{ $labels.instance }}] = {{ $value }} < 1
http://g.pigsty/d/node-instance?var-ins={{ $labels.ins }}
# docker the container engine
- alert: DockerDown
expr: docker_up < 1
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: "WARN DockerDown {{ $labels.ins }}@{{ $labels.instance }}"
description: |
docker_up[ins={{ $labels.ins }}, instance={{ $labels.instance }}] = {{ $value }} < 1
http://g.pigsty/d/node-instance?var-ins={{ $labels.ins }}
# keepalived daemon
- alert: KeepalivedDown
expr: keepalived_up < 1
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: "WARN KeepalivedDown {{ $labels.ins }}@{{ $labels.instance }}"
description: |
keepalived_up[ins={{ $labels.ins }}, instance={{ $labels.instance }}] = {{ $value }} < 1
http://g.pigsty/d/node-instance?var-ins={{ $labels.ins }}
#==============================================================#
# Node : CPU #
#==============================================================#
# cpu usage high : 1m avg cpu usage > 70% for 3m
- alert: NodeCpuHigh
expr: node:ins:cpu_usage_1m > 0.70
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeCpuHigh {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
node:ins:cpu_usage[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} > 70%
# OPTIONAL: one core high
# OPTIONAL: throttled
# OPTIONAL: frequency
# OPTIONAL: steal
#==============================================================#
# Node : Schedule #
#==============================================================#
# node load high : 1m avg standard load > 100% for 3m
- alert: NodeLoadHigh
expr: node:ins:stdload1 > 1
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeLoadHigh {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
node:ins:stdload1[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} > 100%
#==============================================================#
# Node : Memory #
#==============================================================#
# available memory < 10%
- alert: NodeOutOfMem
expr: node:ins:mem_avail < 0.10
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeOutOfMem {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
node:ins:mem_avail[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} < 10%
# commit ratio > 90%
#- alert: NodeMemCommitRatioHigh
# expr: node:ins:mem_commit_ratio > 0.90
# for: 1m
# labels: { level: 1, severity: WARN, category: node }
# annotations:
# summary: 'WARN NodeMemCommitRatioHigh {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
# description: |
# node:ins:mem_commit_ratio[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} > 90%
# OPTIONAL: EDAC Errors
#==============================================================#
# Node : Swap #
#==============================================================#
# swap usage > 1%
- alert: NodeMemSwapped
expr: node:ins:swap_usage > 0.01
for: 5m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeMemSwapped {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
node:ins:swap_usage[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} > 1%
#==============================================================#
# Node : File System #
#==============================================================#
# filesystem usage > 90%
- alert: NodeFsSpaceFull
expr: node:fs:space_usage > 0.90
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeFsSpaceFull {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
node:fs:space_usage[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} > 90%
# inode usage > 90%
- alert: NodeFsFilesFull
expr: node:fs:inode_usage > 0.90
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeFsFilesFull {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
node:fs:inode_usage[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} > 90%
# file descriptor usage > 90%
- alert: NodeFdFull
expr: node:ins:fd_usage > 0.90
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeFdFull {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
node:ins:fd_usage[ins={{ $labels.ins }}] = {{ $value | printf "%.2f" }} > 90%
# OPTIONAL: space predict 1d
# OPTIONAL: filesystem read-only
# OPTIONAL: fast release on disk space
#==============================================================#
# Node : Disk #
#==============================================================#
# read latency > 32ms (typical on pci-e ssd: 100µs)
- alert: NodeDiskSlow
expr: node:dev:disk_read_rt_1m{device="dfa"} > 0.032 or node:dev:disk_write_rt_1m{device="dfa"} > 0.032
for: 1m
labels: { level: 2, severity: INFO, category: node }
annotations:
summary: 'INFO NodeReadSlow {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.6f" }}'
description: |
node:dev:disk_read_rt_1m[ins={{ $labels.ins }}] = {{ $value | printf "%.6f" }} > 32ms
# OPTIONAL: raid card failure
# OPTIONAL: read/write traffic high
# OPTIONAL: read/write latency high
#==============================================================#
# Node : Network #
#==============================================================#
# OPTIONAL: unusual network traffic
# OPTIONAL: interface saturation high
#==============================================================#
# Node : Protocol #
#==============================================================#
# rate(node:ins:tcp_error[1m]) > 1
- alert: NodeTcpErrHigh
expr: rate(node:ins:tcp_error[1m]) > 1
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeTcpErrHigh {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.2f" }}'
description: |
rate(node:ins:tcp_error{ins={{ $labels.ins }}}[1m]) = {{ $value | printf "%.2f" }} > 1
# node:ins:tcp_retrans_ratio1m > 1e-4
- alert: NodeTcpRetransHigh
expr: node:ins:tcp_retrans_ratio1m > 1e-2
for: 1m
labels: { level: 2, severity: INFO, category: node }
annotations:
summary: 'INFO NodeTcpRetransHigh {{ $labels.ins }}@{{ $labels.instance }} {{ $value | printf "%.6f" }}'
description: |
node:ins:tcp_retrans_ratio1m[ins={{ $labels.ins }}] = {{ $value | printf "%.6f" }} > 1%
# OPTIONAL: tcp conn high
# OPTIONAL: udp traffic high
# OPTIONAL: conn track
#==============================================================#
# Node : Time #
#==============================================================#
- alert: NodeTimeDrift
expr: node_timex_sync_status != 1
for: 1m
labels: { level: 1, severity: WARN, category: node }
annotations:
summary: 'WARN NodeTimeDrift {{ $labels.ins }}@{{ $labels.instance }}'
description: |
node_timex_status[ins={{ $labels.ins }}]) = {{ $value | printf "%.6f" }} != 0 or
node_timex_sync_status[ins={{ $labels.ins }}]) = {{ $value | printf "%.6f" }} != 1
# time drift > 64ms
# - alert: NodeTimeDrift
# expr: node:ins:time_drift > 0.064
# for: 1m
# labels: { level: 1, severity: WARN, category: node }
# annotations:
# summary: 'WARN NodeTimeDrift {{ $labels.ins }}@{{ $labels.instance }}'
# description: |
# abs(node_timex_offset_seconds)[ins={{ $labels.ins }}]) = {{ $value | printf "%.6f" }} > 64ms
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.